Architectures GPU
-
Salut à tous
")
J’ouvre ce topic dédié sur les architectures GPU depuis les GeForce 8 et Radeon HD2000^^
On commence avec la génération GeForce 8 et Radeon HD2000:
Tout d’abord, Nvidia sort en premier la première solution desktop employant une architecture unifiée: la Tesla G80 qui animera les célèbre GeForce série 8800. Abritant 681 millions de transistors gravés en 90nm, sa surface atteignait 484 mm², ce qui était un record pour l’époque. Son architecture n’est que la G70 (GeForce 7) en unifiée.
L’organisation de la G80 se fait avec 16 thread processors contenant chacun 8 processeurs de flux (aussi appelé par Nvidia les cores CUDA), ce qui fait un total de 128 unités. Chaque thread processors abrite également son lot d’unités TMU (unités dédiés aux calculs 3D des textures), plus précisément 4 par groupe, pour un total de 64 unités. Mais Nvidia n’en activera que 32 unités.
Le reste se compose des unités ROP (Dédiés aux calculs de l’image et des pixels) qui sont indépendants des thread processors, et sont reliés aux contrôleurs VRAM. Sachant que la G80 abrite 6 contrôleurs 64-bits (pour un total de 384-bits de bus), 6 blocs de ROP sont par conséquent présents. Pour un total de 24 ROP, on a donc 6 blocs de 4 unités.
Le reste se compose d’un Raster Engine (Calcul des triangles), d’une unité de Tesselation (Bien que non exploitable sous DirectX 10) et d’un processeur de commande. On rajoute son contrôleur d’affichage qui gère le multi affichage par DVI, son système SLI (maxi 2 GPU).
Les modèles employant la G80 sont la 8800 Ultra, la 8800 GTX, la 8800 GTS 640MB, et la 8800 GTS 320MB.
Ses dérivés sont la G84 (GeForce 8600) et la G86 (GeForce 8500) qui sont gravées en 80nm.Précisons également que la Tesla possède 2 fréquences d’horloges: une pour les processeurs de flux, et une pour les autres unités. Elles sont indépendantes, et l’OC peut se faire de manière distinctes des 2 composants.
Passons à sa concurrente: les Radeon HD2900 animées par la puce R600. Plus volumineuse que la G80 avec ses 720 millions de transistors, elle est cependant gravée en 80nm, sa surface est donc finalement plus réduite avec ses 420 mm². Son architecture est unifiée comme chez Nvidia, mais son fonctionnement diffère. Alors que Nvidia a opté pour une système dit scalaire, AMD opte pour du vectoriel.
La marketing annonce 320 processeurs de flux, ce qui est à la fois vrai et faux. En réalité, la R600 n’abrite physiquement que 64 unités. Les 320 annoncés n’est que la traduction en scalaire de son fonctionnement afin de la comparer à l’offre Nvidia.
Explication: L’architecture de la R600 est du vectoriel VLIW5, c’est à dire que les unités reçoivent 5 instructions par cycle d’horloges. Cela au contraire du scalaire qui se limite à seulement une seule instruction. Si la R600 est exploitée au max, elle aura donc une puissance équivalente à 320 unités scalaire (car 64x5 = 320).
Pour l’organisation du GPU, elle se compose d’un gros bloc SIMD qui contient 4 petits blocs de 16 processeurs de flux pour 64 unités au total (ou 320 en scalaire). Ces petits blocs abritent également les unités TMU qui sont au nombre de 4 par groupes, donc 16 TMU au total.
Les ROP sont reliés à la VRAM, sauf que le contrôleur mémoire de la R600 est de type ring-bus multidirectionnel. Disposant d’une entrée et sortie ayant chacune une largeur de 512-bits pour un total de 1024-bits (mais seul la sortie est prise en ligne de compte dans les specs, donc 512-bits d’annoncé). Reliés au niveau de la sortie, on a 4 blocs de ROP de 4 unités pour 16 ROP au total.
Tout comme la G80, la R600 dispose de son Raster Engine, l’unité de Tesselation, et du processeur de commande.
Les modèles sont les HD2900 XT, HD2900 Pro et HD2900 GT.
Ses dérivés sont les RV630 (HD2600) et RV610 (HD2400), gravés en 65nm.Voila, j’espère que ça vous plaira. Si c’est le cas, je continuerai bien sur
La suite sera sur les GeForce 9 et Radeon HD3000
-
Ça change des posts habituels, c’est cool
Dans l’attente de la suite -
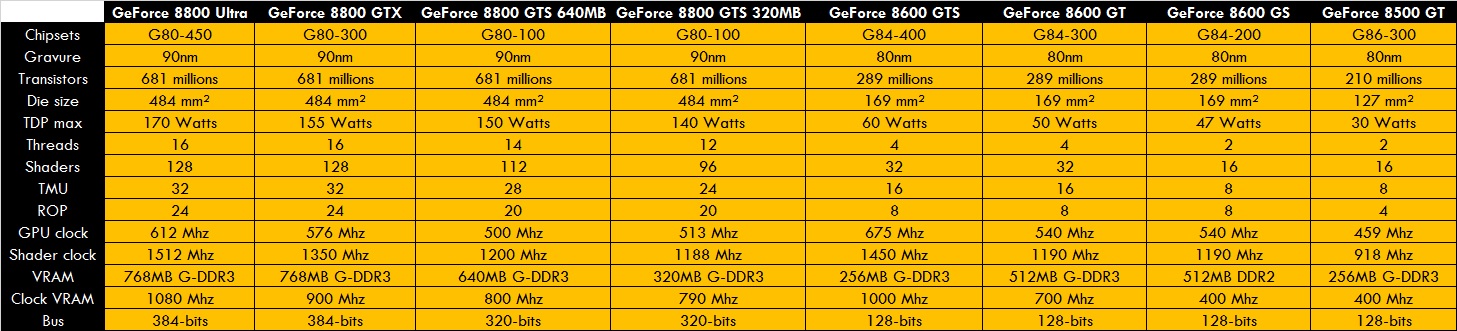
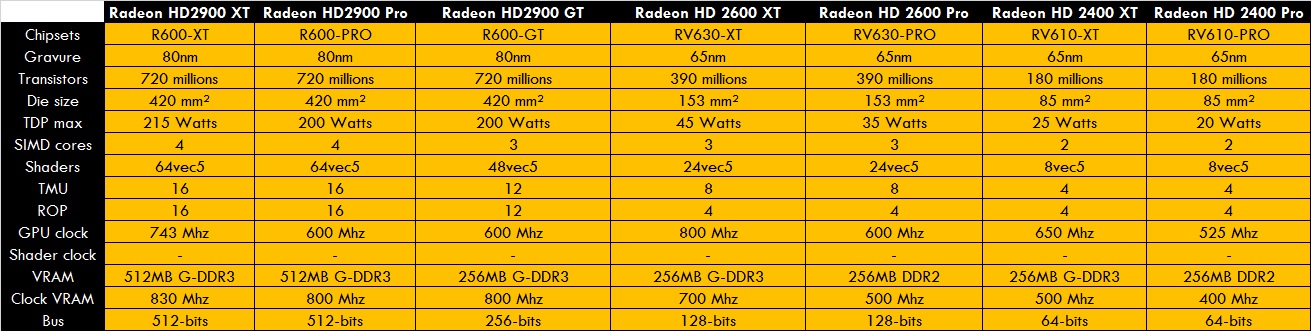
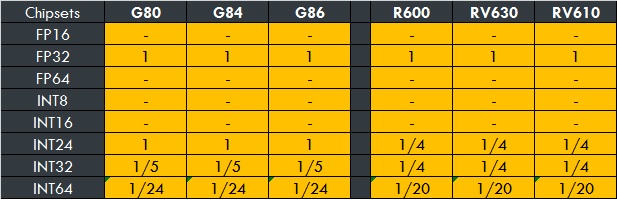
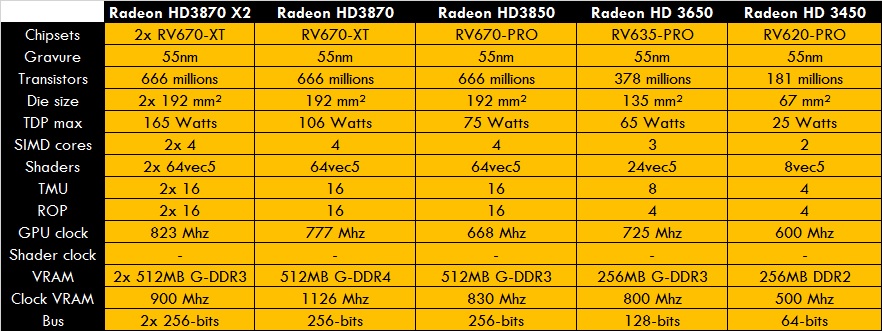
Tableaux qui récapitulent la 1er génération^^
Le 3é tableau donne les ratios des différentes précisions de calcul FP et INT. -
On continue notre lancé avec la génération GeForce 9 et Radeon HD3000:
Nvidia sort peu après les puces G92 avec les GeForce 9800 (Bien qu’elles aient déjà apparus avec les 8800 GTS 512MB et 8800 GT). Gravée en 65 nm, la G92 abrite 754 millions de transistors sous une surface de 324 mm², une diminution notable face à la G80. Son architecture est pratiquement identique à la G80, bien que des modifications soient opérées.
Par exemple, les 64 TMU sont bien actives, cela avec les 128 processeurs de flux répartis en 16 blocs (threads). Cependant, les unités ROP se voient bridées face à la G80: Seulement 16 sont présents physiquement. Ce qui enlève de surcroît 2 contrôleur VRAM 64-bits pour un total de 256-bits.
Pour ce qui reste, la G92 prend en charge le SLI à 4 ponts (contre 2 des G80), le PCI-E 16x 2.0, et enfin le Hybrid-SLI (technique qui consistait à faire un SLI entre une G9x avec un chipset GeForce intégré à la carte mère).
La G92 animera les GeForce 9800 GTX, 9800 GT, ainsi qu’une 9800 GX2 (une bi-GPU). Rajoutons également la 9800 GTX+ qui est comme la 9800 GTX, mais gravée en 55 nm.
Ses dérivés seront les G94 (GeForce 9600), G96 (GeForce 9500) et la G98 (GeForce 9300)La concurrente de la GeForce 9800 GTX est la Radeon HD3870 avec la RV670. Basée sur la R600, elle est gravée en 55 nm avec 666 millions de transistors sous une surface de 192 mm², ce qui en fait de la RV670, le GPU haut de gamme le plus petit conçu (même toujours actuellement). Au niveau architecture, elle s’anime toujours de 4 blocs SIMD de 16 unités pour 64 shaders de type VLIW5, appuyés par 16 TMU.
La RV670 profite de ROP revus et corrigés. Les R600 avaient des problèmes de latences au niveau des ROP dés que les filtrages 3D étaient employés. Toujours au nombre de 16 unités, elles sont reliés au ring-bus qui se voit allégé au passage à 256-bits.
La RV670 est donc une R600 rebadgée? pas tout à fait. Car elle intègre les calculs FP64, la double précision pour les virgules flottantes.
Les cartes concernée sont les HD3870 et HD3850, ainsi qu’une bi-gpu incarnée par HD3870 X2. Rajoutons aussi que la HD3870 emploi de la VRAM G-DDR4.
Ses dérivés seront les RV635 (HD3600) et RV620 (HD3400) qui seront comme les anciennes RV630/610, mais en 55 nm.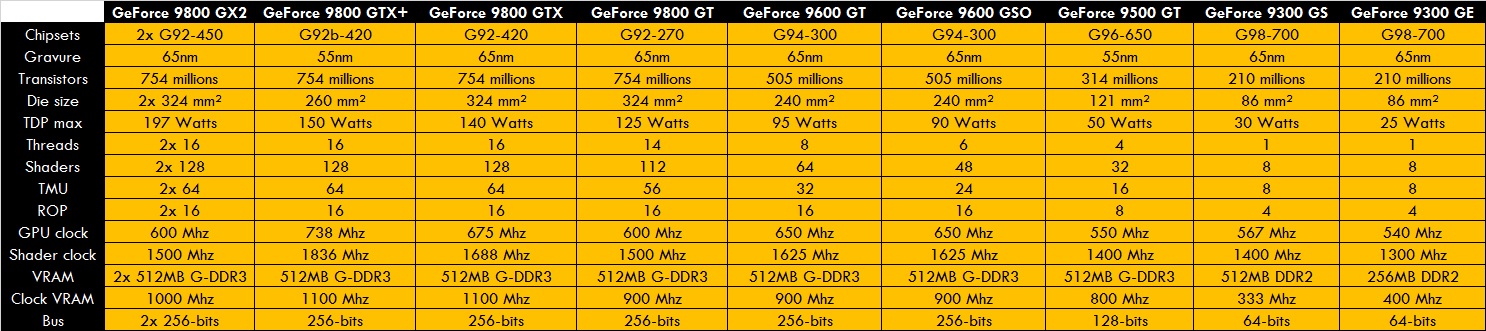
Bonne lecture
-
On continue avec la 3é génération: les GeForce 200 et Radeon HD4000:
Peu après la sortie des GeForce 9800 GTX et GX2, Nvidia sort sa dernière monture haut de gamme avec la GeForce GTX 280. Animée par la GT200, elle utilise l’architecture Tesla 2, car des remaniements et mises à jour ont été effectuées par rapport aux G9x/G8x.
Le GPU est toujours gravé en 65 nm, et abrite 1.4 milliards de transistors sous une surface de 576 mm² (ce qui était énorme, et était le GPU le plus gros jusqu’à ce que la Maxwell GM200 la dépasse).
Nous gardons toujours les threads comme blocs qui abritent les processeurs de flux, mais ceux-ci sont en nombre 30, donc 240 shaders au total, mais l’organisation internet du threads est changé: Alors qu’un thread processor était constitué de 2 cluster de 8 processeurs, la GT200 en intègre 3. Pour les TMU, des changements ont aussi apportés au niveau des branchements: Alors que les TMU étaient liés par groupe de 4 à chaque cluster, on se retrouve avec 8 TMU pleins sous les 3 clusters, donc plus vraiment liés aux clusters comme avant. Avec donc 10 threads processor au sein de la GT200, on totalise 80 TMU.
Peu de changement au niveau des ROP, qui augmentent au nombre de 32 unités, répartis en 8 groupe de 4. Etant liés à 8 contrôleurs VRAM de 64-bits, on se retrouve avec un bus large de 512 bits.
La GT200 intégre les calculs FP64 sous un ratio de 1/8, et gére l’API OpenCL sous sa version 1.1 (Sous OS Mac) et 1.0 (Sous Windows/Linux), avec bien sur CUDA 1.3.
Les modèles sont les GeForce GTX 280 et GTX 260. Les autres GTX 285/275 sont les mêmes, mas gravées en 55 nm. La série aura bien sur une bi-gpu: la GTX 295 (une bi-GTX 275 précisons).
Les dérivés sont les GT215 (GeForce GT 240), GT216 (GT 220) et la GT218 (210/205), identique à la GT200, mais absence du 64 bits.La concurrente, ATI, sort la HD4870 incarnée par la RV770. Animée par l’architecture “TeraScale”, elle est gravée en 55 nm avec ses 956 millions de transistors sous une surface de 256 mm², bien moins grande que la GT200.
Se basant sur la série R600, la RV770 change peu au niveau architecture, hormis des corrections et optimisations nombreuses. Elle abrite en tout 10 blocs SIMD de 16 unités en VLIW5 pour 160 unités, ayant une puissance scalaire de 800 shaders. Les TMU sont toujours avec les blocs SIMD avec 4 unités chacun, donc 40 TMU au total.
Les ROP restent encore au nombre de 16 unités, mais se voient reliés à 4 contrôleurs VRAM 64 bits. ATI met donc fin au ring-bus, jugé trop gourmande et cher. Pour obtenir un gros débit, la HD4870 sera la première carte vidéo à exploiter la GDDR5. La HD4850 est bridée en GDDR3.
La RV770 dispose des calculs en double précisions sous un ratio de 1/5, et prend en charge OpenCL. Notons que la HD4870 et HD4850 ont été les premiers GPU à pouvoir effectuer les premières opérations de minage de crypto-monnaies sous un bon débit. Les GeForce GT200 n’ont été que peu convaincant à ce sujet. L’origine de ses performances plus élevées proviendraient peut-être de l’architecture vectoriel (plus d’instructions) et un débit INT plus poussé. (INT= calcul de nombres entiers).
Les modèles sont les HD4870, HD4850 et HD4830. Il y a également 2 bi-gpu avec les HD4870 X2 et HD4850 X2. Notons la HD4890 qui est une RV790, sorte de RV770 plus optimisée au niveau du rapport Mhz/watt.
Ses dérivés sont la RV740 (HD4700), RV730 (HD4600) et la RV710 (HD4500/4300).


A la prochaine^^
-
On continue avec la 4é génération: les GeForce 400 et Radeon HD5000.
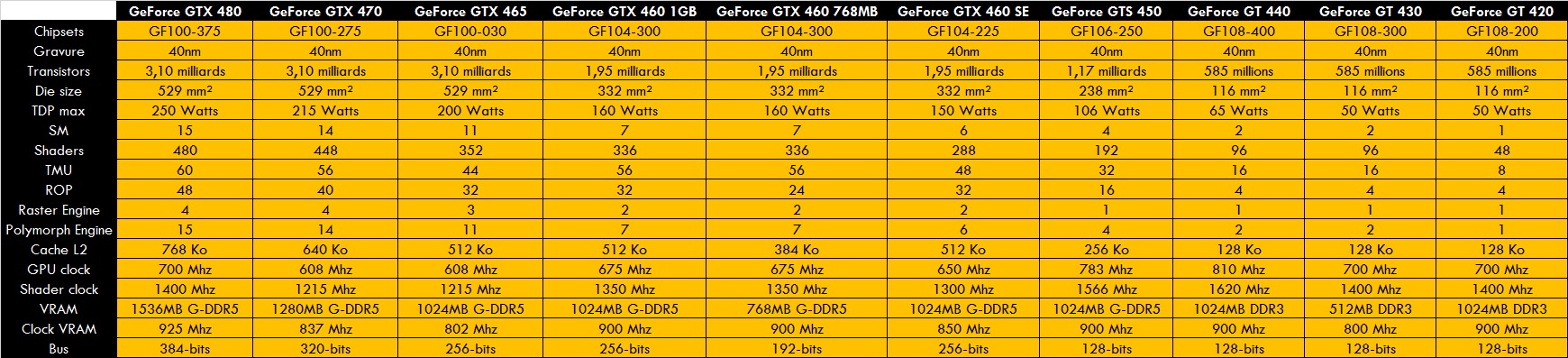
La nouvelle architecture de Nvidia est sortie avec du retard. Se nommant FERMI, elle est un changement radicale face aux TESLA. Fini les threads, place aux blocs SM. Le porte-étendard se nomme la GF100. Gravée en 40 nm, elle abrite 3.2 milliards de transistors sous une surface de 529 mm². Elle dispose de 512 processeurs de flux, dispatchés en 16 blocs SM contenant 32 unités chacun. Mais la GTX 480 n’en activera que 15, donc 480 shaders sont utilisables. Les blocs SM abritent les 32 processeurs, mais aussi divers composants comme les TMU (4 précisément, donc 60 TMU), ainsi qu’un polymorph engine, une unité de calcul géométrique qui remplace l’unité de tesselation des Tesla. La GTX 480 dispose donc de 480 shaders, 60 TMU et 15 Polymorph Engine. Les 16 SM sont disposés dans des gros blocs nommés les GPC. La GF100 a 4 GPC contenant chacun 4 blocs SM. Chaque GPC dispose d’un Raster Engine.
Les unités ROP restent toujours reliés aux contrôleurs VRAM 64-bits qui sont au nombre de 6 pour 384-bits au total. Les 6 blocs de ROP abritent 8 unités, donc 48 ROP au total. Notons aussi l’apparition d’une mémoire cache L2 relié aux ROP et contrôleurs VRAM. Divisé en 6 parties de 128 Ko, on a donc un cache L2 de 768 Ko.
Autre changement: les fréquences. Tout comme les Tesla, les shaders et autres composants ont une fréquence spécifique, mais au contraire des Tesla où elles étaient indépendantes, celles des FERMI sont liées. Ainsi, la fréquence shaders est le double de la fréquence des autres unités. Un OC de la fréquence 3D augmentera automatiquement la fréquence shaders.
Les modèles sont les GTX 480, GTX 470 et la GTX 465. Les dérivés sont les GF104 (GTX 460), les GF106 (GTS 450) et les GF108 (GT 440/430). Notons que les dérivés se basent sur des blocs SM de 48 unités.
Le concurrent ATI, sort en premier la HD5870 alias la CYPRESS (aussi nommé en code RV870). Gravée en 40 nm, elle abrite 2.154 milliards de transistors sous une surface de 336 mm². Animée par l’architecture “TeraScale 2”, elle se base sur la RV770.
La RV870 se compose de 20 blocs SIMD de 16 unités VLIW5 pour 320 processeurs de flux (1600 shaders en scalaire). Toujours avec 4 TMU par blocs, on a donc 80 TMU au total. On a droit à 2 Raster Engine et une unité de tesselation.
Les unités ROP restent indépendants des blocs SIMD, et sont reliés aux 4 contrôleurs VRAM 64-bits pour 256-bits au total. Pour 32 ROP au total, donc on a donc 4 blocs de 8 unités. Tout comme les GeForce, la CYPRESS dispose d’un cache L2 de 512 Ko, donc 4 parties de 128 Ko.
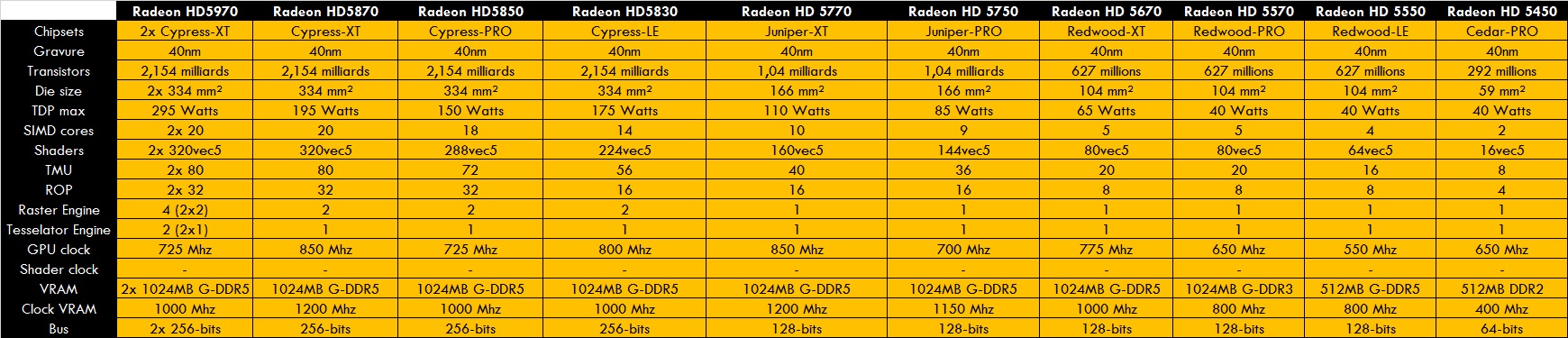
Les modèles sont les HD5870, HD5850 et HD5830. On a aussi une bi-gpu, la HD5970. Ses derivés sont la JUNIPER RV840 (HD5700), la REDWOOD RV830 (HD5600/5500) et la petite CEDAR RV810 (HD5400).
Les HD5870 et HD5850 furent le summum du minage pendant les premiers jours du Bitcoin.
A la prochaine
-
On continue avec la 4é génération: GeForce 500 et Radeon HD6000:
En soit, les GeForce 500 ne sont que les GeForce 400, mais améliorées au niveau du TDP. Hormis cela, l’architecture reste inchangée.
La GTX 580 utilise la GF110 qui se retrouve à 3.1 milliards de transistors pour 520 mm² de surface, ceci par l’optimisation de la gravure. Les 16 blocs SM sont actifs, ce qui donne 512 shaders et 64 TMU en tout.
Rien de changer au niveau des ROP et des interfaces: 48 ROP liés à bus VRAM de 384-bits et un cache L2 de 768 Ko.
Les modèles sont les GTX 580, GTX 570 et GTX 560 Ti 448 cores. Les dérivés optimisés sont les GF114 (GTX 560), les GF116 (GTX 550), et la petite GF119 (GT 520). Les GF108 restent en version 1 niveau gravure.
La nouveauté de la série 500 est la GTX 590, une bi-GTX 580.
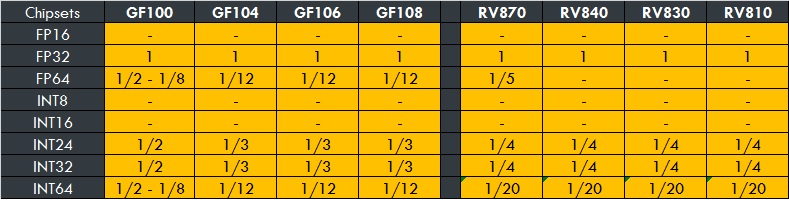
Du coté de la concurrence AMD, des nouveautés sont présentes en revanche. Les HD6900 emploient une architecture certe toujours vectorielle, mais nouvelle au niveau du fonctionnement. Alors que les autres GPU AMD fonctionnent en VLIW5, les HD6900 tournent en VLIW4, donc 4 instructions. Le GPU concerné se nomme CAYMAN, abritant 2.64 milliards de transistors sous une surface de 389 mm². Son architecture spécifique à elle seule est le “TeraScale 3”. Elle intègre 24 blocs SIMD de 16 unités en VLIW4, donc 384 processeurs de flux (ou 1536 en scalaire). Le nombre de ROP reste inchangé par groupe (Toujours 4), mais avec 4 blocs en plus, on grimpe à 96 unités.
Rien de changer au niveau des ROP qui restent à 32 ROP liés à 4 contrôleurs VRAM pour 256 bits, et un cache L2 de 512 Ko.
Les modèles sont les HD6970, HD6950 et HD6930. On a droit comme d’habitude a une bi-gpu: la HD6990.
Ses dérivés sont les BARTS (HD6800), JUNIPER (HD6700), TURKS (HD6600/6500) et CAICOS (HD6400). Ces GPU la, bien que nouvelles au niveau des spécificités reprennent une architecture TeraScale 2, donc VLIW5.


A la prochaine
-
On continue avec la 5é génération qui s’étend sur 2 familles: les GeForce 600/700 et les Radeon HD7000 et Rx-200
AMD sort en premier son premier GPU gravé en 28 nm: la TAHITI. Elle abrite 4.31 milliards de transistors sous une surface de 352 mm².
Elle est animée par une toute nouvelle architecture nommée GCN (Graphic Core Next). Au revoir le vectoriel VLIW, et passons au scalaire comme chez Nvidia. Les blocs SIMD sont remplacés par les CU (Compute Unit) qui abrite chacun 64 processeurs de flux scalaire. La TAHITI en possédant 32, elle dispose de 2048 shaders. Les TMU restent toujours aux cotés des shaders, et chaque CU dispose de 4 TMU, donc 128 TMU au total. Les 32 CU sont répartis dans de gros ensembles nommés les Shader Array (au nombre de 4) que abritent 8 CU chacun. On a ensuite les Shaders Engine (2) qui contiennent les Raster Engine et unités de Tesselation. On a également l’apparition des ACE (Asynchrone Comput Engine) qui permettent d’envoyer plus d’instructions aux shaders, et chaque ACE peuvent envoyer 2 threads par cycle d’horloges.
Les ROP sont installés au cotés des CU tout en restant indépendants, et ne sont plus liés aux contrôleurs VRAM. Il y a 8 partitions d’installées contenant chacun 4 ROP et 16 Z/Stencil, pour un total de 32 ROP et 128 Z/Stencil. Les Z/Stencil sont les unités qui gèrent les couleurs de l’affichage.
La TAHITI s’appui d’un cache L2 de 768 Ko divisé en 6 partitions de 128 Ko, car liés aux 6 contrôleurs de 64-bits pour un total de 384-bits.
Les modèles sont les HD7970, HD7950 et HD7870 XT. Une bi-GPU est également sortie avec la HD7990.
Ses dérivés de sa génération sont les PITCAIRN (HD7800), les CAPE VERDE (HD7700) et une BONAIRE (HD7790).
Ce n’est qu’à partir des Radeon Rx-200 qu’AMD sort la HAWAII, une puce haut de gamme qui abrite 6.2 milliards de transistors sous une surface de 438 mm². Son architecture reste du GCN, mais sous sa 2é version (GCN2) et avec quelques modifications: comme les Shaders Array et Engine qui fusionnent. La HAWAII dispose de 44 CU pour 2816 shaders et 176 TMU. Le nombre de ROP a été augmenté à 64 unités, avec ses 256 Z/Stencil. La Cache L2 a été boosté à 1024 Ko, et le bus atteint 512 bits avec 8 contrôleurs 64-bits. Avec 4 Raster Engine et 4 unités de Tesselation, la Hawaii se voit accompagné de 8 ACE plus efficaces: 8 threads (contre 2 des GCN1).
Les modèles concernés sont les Radeon R9 290X et 290, avec une bi-GPU: la R9 295X2. La puce BONAIRE suit la même itération architecturale que HAWAII (R7 260). Les autres seront du renommages avec les R9 280/270.
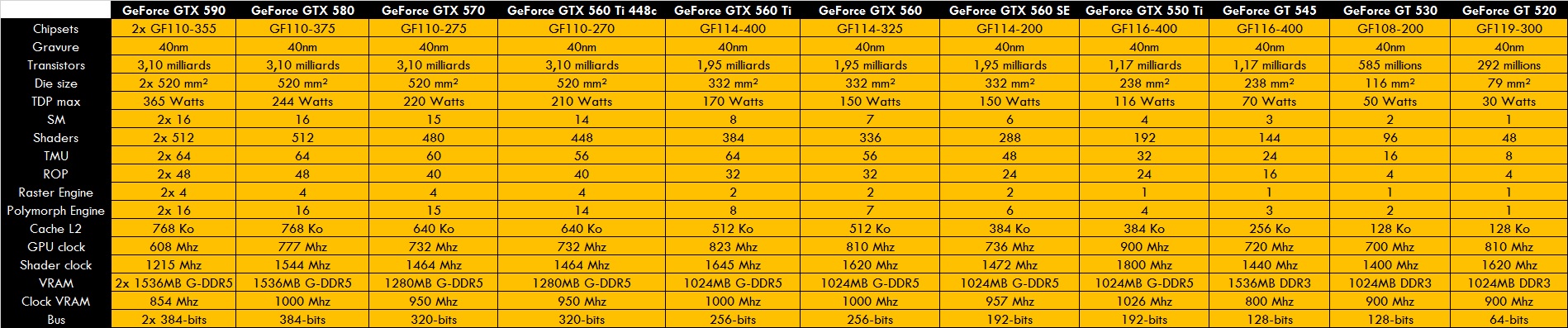
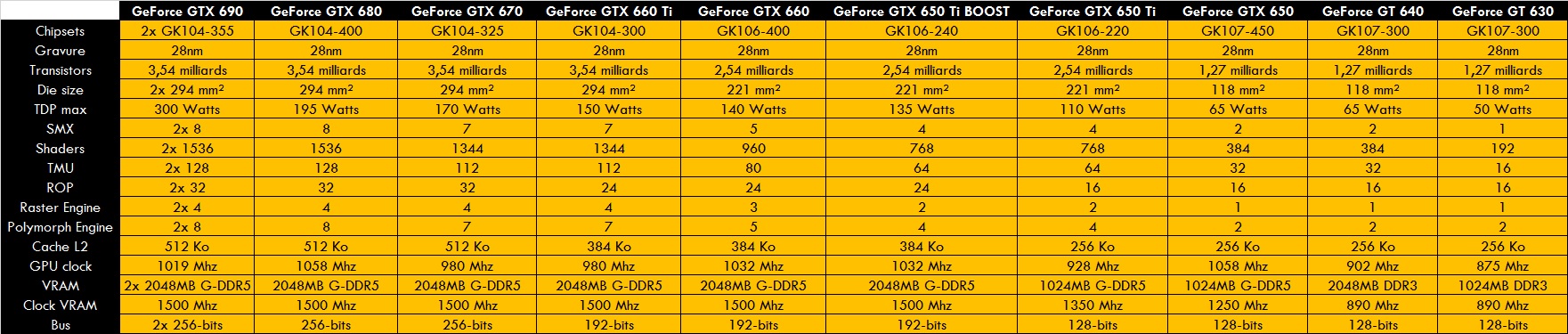
Nvidia sortira peu après sa GTX 680 qui utilise la nouvelle architecture KEPLER. Au lieu de se baser sur des cores SM de 32 unités (des GF100 FERMI), KEPLER se base sur des SMX de 192 unités, donc bien plus vaste. La GTX 680 se base sur la GK104, donc pas le haut de gamme face aux TAHITI. Gravée en 28 nm, elle abrite 3.54 milliards de transistors sous une surface de 294 mm².
La GK104 dispose de 8 SMX, donc 1536 shaders au total. Les TMU sont toujours au sein des blocs SMx, mais en groupe de 16, donc 128 au total. Les Polymorph Engine sont au nombre de 8 (car chacun dans les SMX). Les gros GPC sont au nombre de 4, abritant les 2 SMX et le Raster Engine.
Les ROP sont au nombre de 32 unités répartis en 4 groupes de 8, avec les 4 contrôleurs VRAM de 64 bits pour un total de 256 bits. La mémoire cache L2 est de 512 Ko.
Autre changement: il n’y a plus 2 fréquences d’horloges (3D et Shaders). On se retrouve avec une seule et unique fréquence qui anime tout le GPU comme chez AMD.
Les modèles concernés sont les GTX 680, GTX 670 et GTX 660 Ti, avec une bi-GPU sous la GTX 690.
Le haut de gamme avec la GK110 sort sous les GTX Titan et GTX 780 pour contrer HAWAII. La GK110 abrite 7.08 milliards de transistors sous une surface de 561 mm². Avec 15 SMX, la GK110 dispose de 2880 shaders et 240 TMU.
Avec 5 GPC, la GK110 dispose de 5 Raster Engine.La cache L2 est augmenté à 1536 Ko avec les 6 contrôleurs de 64 bits, pour 384 bits au total. Le tout avec les 6 partitions de 8 ROP, pour 48 unités au total.
Les modèles sont les GTX Titan Black, GTX Titan, GTX 780 Ti et GTX 780. La différence est que les Titan ont les calculs en double précision à pleine vitesse. On aura droit a une bi-Titan avec la GTX Titan Z.
PS: Je ferai les tableaux après^^
A la prochaine
-
Les tableaux comme promis^^
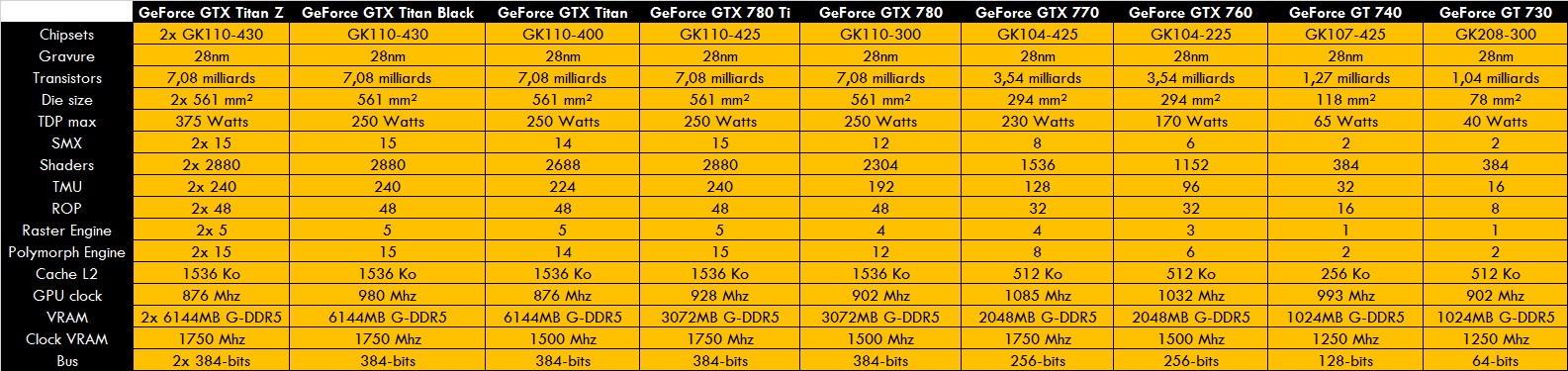
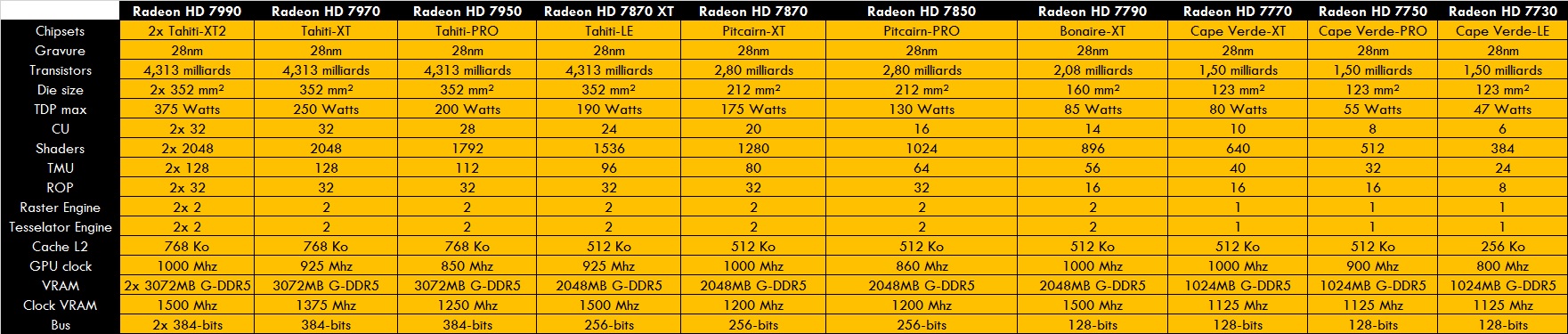


A la prochaine
-
On continue avec la 6é génération sous les GeForce 900 et les Radeon Rx-300:
Nvidia sort la GTX 980 animée par la GM204. Nouvelle architecture nommée MAXWELL. Gravée en 28 nm, la GM204 abrite 5.2 milliards de transistors sous une surface de 398 mm². La nouvelle architecture optimise pas mal de choses.
Les blocs SM (nommés SMM) abritent chacun 128 cores CUDA (diminution donc face aux SMX Kepler) et 8 TMU. La GM204 en possédant 16 de ces blocs, on a donc 2048 shaders et 128 TMU. L’architecture Maxwell répond à certaines problématiques. Déjà, la GM204 dispose d’une bonne prestation en matière de GPGPU (domaine qui faisait défaut aux Kepler et qui était jusqu’ici l’exclusivité des FERMI). En plus de gérer enfin la version 1.2 de OpenCL, Maxwell intègre enfin une bonne puissance de calcul avec cet API. Certe, toujours en dessous des GCN d’AMD, mais au moins correct pour proposer une alternative. Le calcul du minage par exemple a reçu un sacré bond aux Kepler où une simple GTX 750 Ti dépasse une GTX 680…Autre point de résolu: la consommation. Maxwell allie donc consommation maîtrisée et bonne puissance 3D et GPGPU. Kepler n’avait que la consommation et 3D (au détriment du GPGPU) et FERMI avait la 3D et GPGPU (mais au détriment de la consommation)…
La GM204 s’articule autour de 4 GPC possédant 4 SMM chacun. Chacun ont leur Raster Engine.
Les ROP sont au nombre de 64 unités, dispatchés en 4 partitions de 16 unités. Le tout reliés aux 4 contrôleurs VRAM de 64-bits pour un total de 256-bits. La mémoire cache L2 se voit bien augmenté: 2048 Ko.
Les modèles sont les GTX 980 et GTX 970. Pas de bi-GPU, ce qui dommage étant donné ses bonnes prestations en niveau de la consommation.
Reste ensuite le très haut de gamme avec la GM200 qui anime les GTX Titan X et GTX 980 Ti. En soit, ce n’est que la GM204 boosté aux hormones. Avec ses 8 milliards de transistors sous 601 mm² de surface (ce qui en fait au passage du GPU le gros jamais conçu), elle abrite 24 SMM pour 3072 shaders et 192 TMU. Avec un bus de 384-bits, on a donc 6 partitions de 16 ROP pour 96 unités au total, et un cache L2 de 3072 Ko.
Pour AMD, on passe à GCN3 pour les grosses puces FIJI et la petite TONGA. La 3é version de GCN intègre les calculs 16 bits en FP et INT, et la compression des données au niveau des unités ROP. Rajoutons l’ajout du HWS, une unité asynchrone comme les ACE mais qui a la capacité d’être modulaire au niveau du micro-code, donc modifiable et adaptable selon les besoins des professionnels.
FIJI est une grosse puce de 8.9 milliards de transistors sous une surface de 598 mm². Avec ses 64 CU, elle dispose de 4096 shaders et 256 TMU. Les unités restent par contre à 64 unités.
FIJI inaugure également avec la VRAM HBM qui permet une plus grande bande passante, tout en réduisant l’espace sur le PCB de la carte graphique. La R9 FURY X dispose de 4 Go HBM répartis en 4 puces de 1 Go. Dans le GPU, les contrôleurs VRAM sont au nombre de 8, d’une largeur de 512-bits, pour un total de 4096-bits. 2 contrôleurs 512-bits sont liés à la puce HBM de 1024-bits. La mémoire cache L2 est augmentée à 2048 Ko, pour 8 partitions de 256 Ko par contrôleurs.
TONGA est de son coté très proche de TAHITI avec ses 32 CU, ses 2048 shaders, 128 TMU et ses 32 ROP. Seules différences que le cache L2 est abaissé à 512 Ko, et l’intégration des calculs 16-bits et de l’unité asynchrone HWS.
Les modèles FIJI sont les R9 FURY X, R9 FURY et R9 NANO. Une bi-GPU est également de la parti avec la PRO Duo.
Les TONGA seront les R9 380X et R9 380. Les autres seront du renommage avec les R9 390(X) HAWAII et les 370/360 Pitcairn et Bonaire.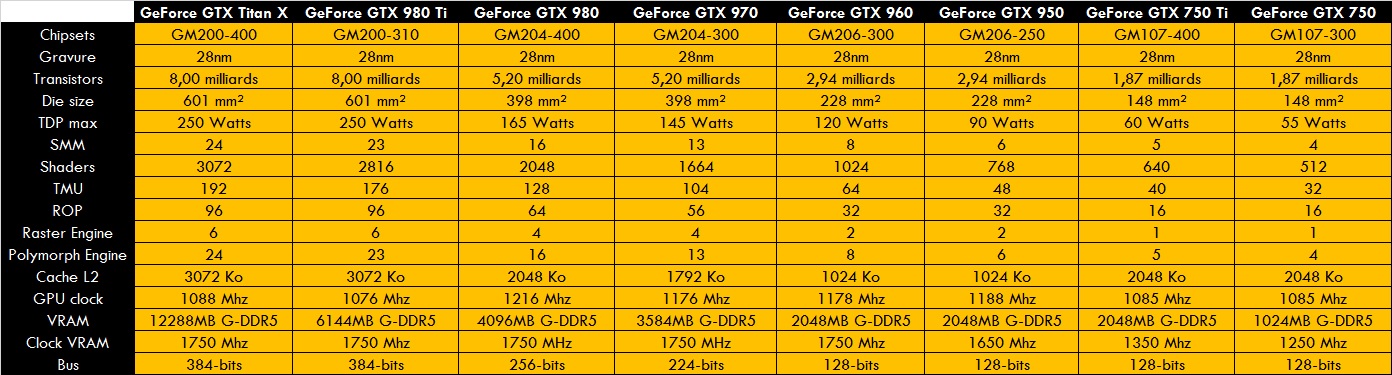
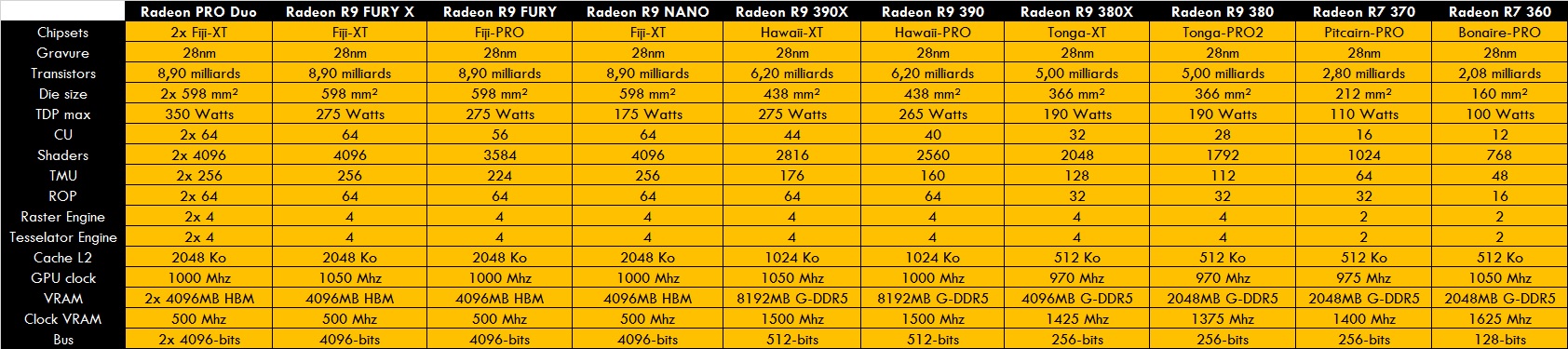

A la prochaine
-
On continue avec la 7é génération sous les GeForce 1000 et les Radeon RX-400.
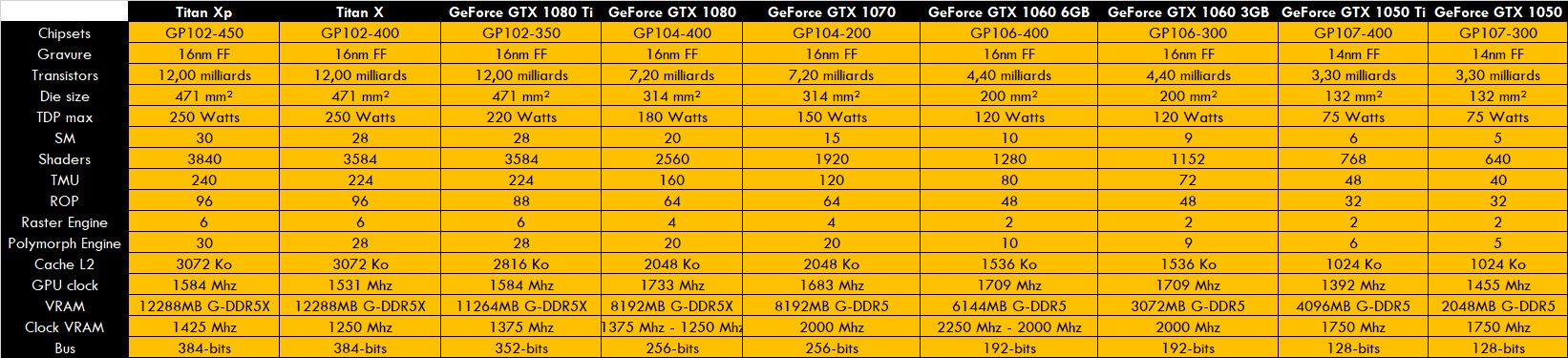
Nvidia commence le bal avec les GTX 1080 et GTX 1070 animées par la GP104. L’architecture se nomme PASCAL. Gravée en 16nmFF, elle abrite 7.2 milliards de transistors sous une surface de 314 mm². Son architecture est basée sur MAXWELL, peu de choses ont changés. On a toujours affaire à des SM de 128 shaders, hormis qu’on en a 20 (au lieu de 16 des GM204), ce qui nous fait 2560 shaders et 160 TMU.
Le nombre de ROP reste à 64 unités, reliées à 4 contrôleurs VRAM de 64-bits, et un cache L2 de 2048 Ko.
Donc une question se pose: En quoi PASCAL est différent de MAXWELL? Bon on peut déjà dire que la gravure améliore beaucoup les choses: baisse de la consommation, plus d’unités shaders…mais sans plus. PASCAL est en soit une sorte de MAXWELL-REFRESH, mise à jour au niveau de la gravure. Nvidia semble se concentrer sur le ratio des fréquences. En effet, les puces PASCAL ont une fréquences très hautes: Plus de 1700 Mhz, et pouvant s’overclocker facilement à 2000 Mhz. Autant dire que PASCAL est de la force brute par la fréquence plutôt que par l’architecture en elle-même. On peut toutefois noter l’apparition du FP16 comme chez AMD (à partir des GCN3), mais à un débit très bas: 1/64 du FP32.
Peu après, on a la GP102 qui est tout simplement la GM200 boostée aux hormones: 30 SM (au lieu de 24) et fréquences à plus de 1500 Mhz au lieu de 1070 Mhz.
Les GeForce 1000 gèrent la nouvelle mémoire GDDR5X, plus rapide que la GDDR5 et à moindre coût face au HBM. Elle est cependant employée que pour les modèles haut de gamme.
La seule nouveauté qu’on peut constater est la GP100, disponible que chez les pros. Animée par une architecture bien différente des autres, car se basant sur des SM de 64 unités, et disposant de mémoire cache plus volumineux, comme le cache L2 à 4096 Ko. La GP100 dispose du FP16 à 2x la vitesse du FP32, et le FP64 à la moitié du FP32. N’oublions pas que la GP100 utilise la nouvelle mémoire HBM2 en 4096-bits pour presque 800 Go/s .
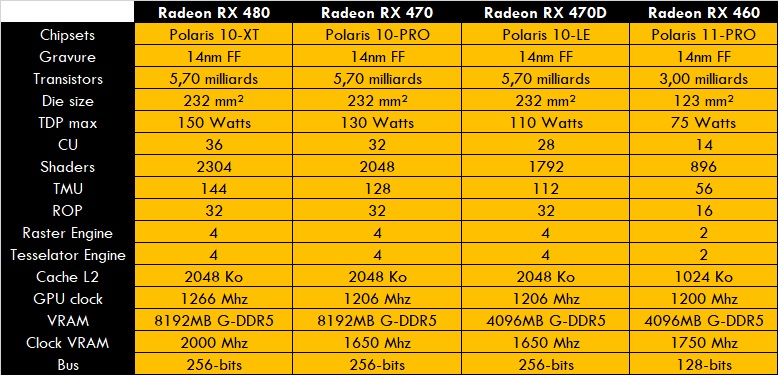
Du coté d’AMD, on a pour le moment que la gamme moyenne incarnée par les POLARIS, ou plutôt les AMD GCN4. La Radeon RX 480 utilise la POLARIS 10 plutôt nommée la ELLESMERE. Gravée en 14nmFF, elle abrite 5.7 milliards de transistors sous une surface de 232 mm². Son architecture se base beaucoup sur les acquis des GCN3, et aussi, peu de choses ont changés. AMD se concentrant sur la rapport perf/watt, ce qui est en soit réussi avec seulement 150 Watts de TDP pour des perfs identiques aux R9 290X qui pointaient à 290 Watts.
ELLESMERE dispose de 36 CU de 64 unités pour 2304 shaders au total et 144 TMU. Le nombre de ROP reste à 32 unités, mais elles ont été bien améliorés, à en juger les perfs 3D face aux HAWAII qui avaient 64 de ces unités.
Les modifications notables sont au niveau de la VRAM et du cache L2. Au lieu de contrôleurs de 64-bits, on a affaire à des 32-bits, au nombre de 8 pour faire 256-bits. Le cache L2 a été augmenté à 2048 Ko, bien au dessus des 512 Ko des AMD TONGA.
On a toujours les calculs FP16 à vitesse égale au FP32, et les unités asynchrones HWS modifiables pour les pros.
Les modèles concernés sont les Radeon RX 480 et 470. La petite POLARIS 11 (ou BAFFIN) anime l’unique Radeon RX 460.
Elles seront mises à jour avec les RX 580/570/560, avec une petite nouvelle, la RX 550 animée par la POLARIS 12 (ou LEXO).

A la prochaine